Introduction To Recurrent Neural Network
The Feed Forward Neural Network can't model every model every problems today. The main problem faced by the feed forward network is that it can't handle sequential data. Sequential data is the data in sequence.
Recurrent Neural Network is a type of neural network where the output from the previous step is fed as input to the current step. In traditional neural network, all the inputs and outputs are independent of each other. But in cases where it is required to predict the next word of a sentence , or the next frame of a video, or the next pixel in an image . The previous word are required and hence there is a need to remember the previous words.
RNN solved this problem with the help of the hidden layer which is the main and the most important feature of RNN which remember some information about a sequence and it is also referred to as Memory state since it remember the previous input of the network.
The Purpose and Need for RNN
Recurrent neural network was Developed to address the limitations of traditional feed forward network. When dealing with Sequential data, In FNN information flows in one direction , from input to ouput, without any form of memory. This design is suitable for task where input and output are independent of each other, such as image classification. However many real worlds problem involve sequences, where the order and context of data points matter. for example , In NLP understanding a word meaning often depends on the words that came before it in a sentence.
RNN were Developed to handle such situations by introducing the concept of "recurrent" connections, allowing them to maintain a hidden state that captures information from the previous time steps.
RNN process the sequential data step by step with each step taking an input and updating its hidden state.
Working of Recurrent Neural Network :-
One of the disadvantage of modelling sequence with traditional neural network is the fact that they don't share parameters accross time. Let's take an example "It was raining on tuesday" and "On Tuesday , it was raining" both of these sentences mean the same thing although the details are in different manner or sequence. When we feed these sentences to the feed forward network fo prediction task, the model will assign different weights to "On tuesday" and "it was raining" at each moment of time. Sharing the parameter gives the network the ability to look for a given feature everywhere, rather then in just a certain area.
We need a specific framwork that will be able to deal with :-
1. Variable length sequence
2. Maintain sequence order
3. Keep track of long-term dependencies rather then cutting input data too short.
4. Share the parameter accross the sequence.
RNN is a type of neural network architecture that use a feedback loop in the hidden layer.
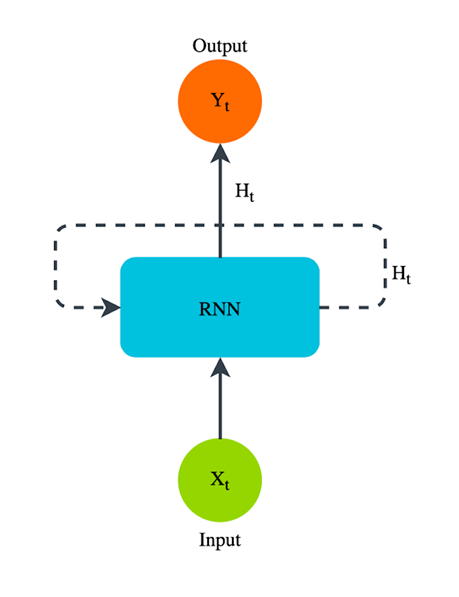
Sometimes the Recurrent Neural Network depicted over time like this :-
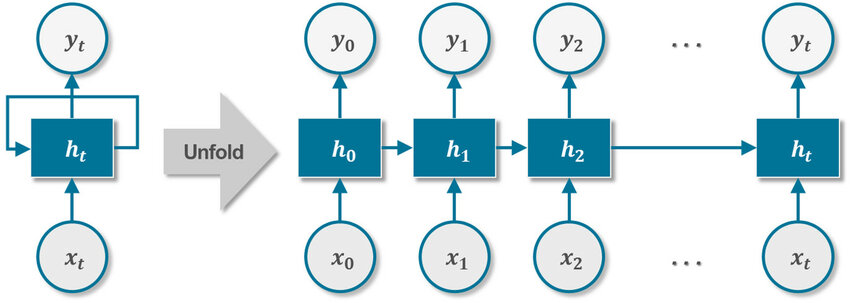
In this architecture, h is the hidden node , x is the input and y is the output node.
1. The First path represents the network in the first time step. the hidden node h0 uses the input x 0 to produce the output y 0 , this is what we happen to see in FFN also (only the first step).
2. At the second step the hidden node at the current time step h 1 uses both new input x 1 as well as the state from the previous time step h 0as input to make new prediction. This means that a current node uses knowledge of its previous hidden state and take it as input for its current prediction.
How do we train RNN :-
1. Uses the Backpropagation algorithm.
2. Backpropagation is applied for every sequence data point rather then the entire sequence.
3. This Algorithm Sometimes called Backpropagation through time (BTT).
Intelligent Predicting :-
Imagine we are creating a RNN to predict the next letter a person likely to type based on the previous letter they have already typed.
Issues With RNN :-
Known as Short-Term memory, which is caused by infamous vanishing and exploading gradient. As the RNN processes more words , it has trouble retaining information from the previous steps, kind of like our memory.
Exploading and Vanishing gradient problem comes due to the nature of Backpropagation, the algorithm used to train and optimize the neural network. After the Forward propagation process is complete, the network compares the predicted value to the expected value using loss function, which ouputs the error value.
Error = (Predicted output - Expected output) 2
The Network uses that error value to perform Backpropagation which calculates the gradient for each nodes in the network. The gradient is the value used to adjust the network internal weights, allowing the network to learn, the bigger the gradient , the bigger the adjustment are made.
When performing backpropagation, each node in a layer calculates its gradient with respect to the effects of the gradient in the layer before it. If the adjustment made to the layer before it is small, then the adjustment to the current layer will be even smaller. This causes the gradient to exponentially shrink as it backpropagates down. Consequently, the earlier layers fail to undergo significant learning, as the internal weights are barely being adjusted due to the extremely small gradient. This phenomenon is known as the vanishing gradient problem.
Because of Vanishing gradient problem, the RNN doesn't learn the long range dependencies across time steps, this means that in a sequence "it was raining on tuesday", there is possibility that the word "it" and "was" not considered when trying to predict the user intention.
The Network then has to make best guesses with "on tuesday" and that's pretty ambiguous and would be difficult for a human also , so not being able to learn long sequences is a major issue with Recurrent Neural Networks(RNN) and causes the network to have short term memory.
We can Combat the Short-Term Memory problem of RNN by using two variants of RNN :-
1. LSTM : Long Short-Term Memory
2. GRU : Gated Recurrent Unit.
Long Short-Term Memory (LSTML) :-
It is a type of recurrent neural network that is designed to learn long-term dependencies in sequential data. LSTM network is capable of processing and analyzing data like text and speech. LSTM was designed to address the short-term memory problem.
LSTML uses Memory Cells and Gates to control the flow of information, allowing them to selectively retain or discard information as needed and this makes them highly effective in understanding patterns in the sequential data. Memory Cells can store and retrieve information over long sequences and Gates are used to control the flow of information
How Gates Control the flow of information ?
There are three types of gates in LSTM which are Forget Gate which determines what information from the previous states should be discarded and next is Input Gate which modifies the state with new information and the last gate is Output Gate which produces the output based on modified or updated states.
Advantages of RNN :-
1. Sequential data Processing
2. Paramter Sharing
3. Flexible
4. Capable of storing Previous Inputs
Disadvantages of RNN :-
1. Vanishing Gradient Problem
2. Exploading Gradient Problem
3. Difficulty in Remembering Long-Term Dependencies
4. Training an RNN is a very difficult task
Bidirectional Neural Network
Bidirectional is a variant of RNN and it is a type of neural network that process sequential data in both forward and backward direction and then the output of both direction are combined to produce the final output of the bidirectional network.
BiNN is useful for tasks that require understanding from both past and future context, such as speech recognition or machine translation.
BiNN is typically implemented as two separate RNN, one process the data in the forward direction and other that process the data in the backward direction.
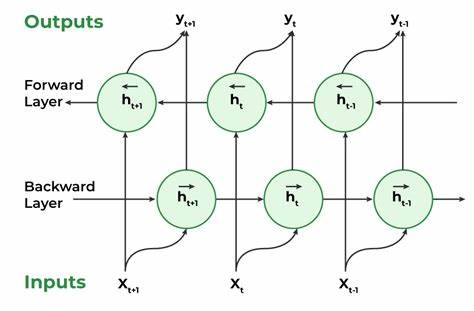
BiNN has been shown to be very effective for variety of NPL tasks :-
1. Language Modeling : Predicting the next word in a sequence given the previous words.
2. Machine translation : Translating text from one language to other.
3. Named Entity Recognition : Identifying name entities in text, such as people , places or organizations.
For Example : We have two sentences one is "John(person) loves apple(fruit), it keeps him healty" and other is "John(person) loves apple(company), the company produces best phones". The word which comes prior to apple they are same until you look at the sentence after apple, you won't know of the apple is a fruit or a company. If you look at your simple RNN which moves in a single direction (left to right). the word "apple" will have influence only based on the context preceding it. This is because the hidden state of the RNN at a given time step depends on the information it has seen up to that point. As the network processes each word in sequence, it updates its hidden state, and this state carries the information about the context.
Advantages of BiNN :-
1. Improved Accuracy
2. Reduced Information loss
3. Better Contextual understanding
Disadvantages of BiNN :-
1. Increased Computational Complexity
2. Potential Overfitting
3. Complexity which makes bidirectional models harder to interpret
Next Page