Introduction To Machine Learning
To Understand Deep Learning , we must understand what is Machine Learning is first. Machine learning is an application of artificial intelligence that involves algorithms and data that automatically analyse and make decisions without human intervention. It describes how computer perform tasks on their own by previous experiences. Therefore we can say in machine language artificial intelligence is generated on the basis of experience. “Learning is any process by which a system improves performance from experience.”
Machine Learning is alternatively termed shallow learning because it is very effective for smaller datasets.Deep Learning is extremely powerful when the dataset is large.
Deep Learning is a subset of machine learning that uses artificial neural networks to learn from the data which we will learn later.Articficial neural networks are inspired by the structure and function of the human brain , and they are able to learn Complex patterns from large amounts of data.
Approach:- Deep Learning uses Artificial Neural Networks to learn from Complex Patters from Large Dataset. Machine Learning uses variety if techniques to learn from the data , such as linear regression , decision tree , etc.
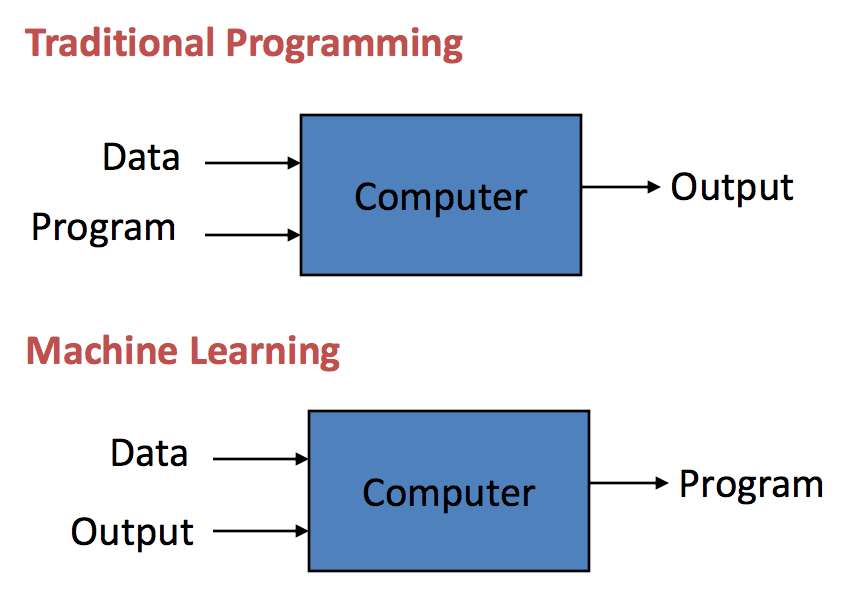
Normal Computer vs Machine Learning
The difference between normal computer software and machine learning is that a human developer hasn’t given codes that instructs the system how to react to situation, instead it is being trained by a large number of data.
Some of the machine learning algorithms are:
1. Neural Networks :- Algorithm inspired by the neurons of the human brains just like neurons make up the brain , the fundamanetal building blocks of a neural network is also a neuron. Neural networks are used to recognize patterns, make predictions, and perform tasks that typically require human-like intelligence.
2.Random Forest :-A Random Forest is an ensemble learning method used for both classification and regression tasks in machine learning. The "forest" in Random Forest is a collection of decision trees, where each tree is built independently and operates by making a decision based on the majority vote of its constituent trees.
3. Decision Tree :-A decision tree algorithm is a machine learning technique used for both classification and regression tasks. It works by recursively partitioning the data into subsets based on the input features, and at each node of the tree, a decision is made based on a feature to split the data.
Some tasks that are best solved by using a learning algorithm:
1. Recognizing Patterns:- Facial identities or facial experssions , This involves the recognition and differentiation of individuals based on their facial features.Facial recognition technology analyzes key facial landmarks and patterns to create a unique identifier for each person. This is commonly used in security systems, authentication processes, and even social media tagging. AI can also be trained to recognize and interpret facial expressions to understand human emotions. This has applications in human-computer interaction, sentiment analysis, and psychological research.
2. Image and Speech Recognition:- Image recognition, also known as computer vision, is the process of training a machine learning model to interpret and understand visual information from images or videos.
3. Recognizing anomalies:- Identifying unusual patterns or outliers in data that may indicate errors, fraud, or system malfunctions. for example Unusual credit card transactions , Unusual patterns of sensor readings in a nuclear power plant.
4. Prediction:- Recommending movies, products, or articles based on user preferences and historical behavior.
5 Recommendation Systems :- Machine learning algorithms are particularly well-suited for tasks that involve prediction or inference based on patterns learned from data. for example Future stock prices or currency exchange rates.
Types of Machine Learning:
1. Supervised (inductive) learning:- (Given: training data + desired outputs (labels)). The Supervised learning is a type of Machine learning in which algorithm is trained on a set of labelled data , where each input has a known output. an algorithm learns from a labeled dataset to make predictions or classifications on new, unseen data.
The Supervised Learning Algorithm are typically divided into two main categories : Classification and Regression.Classification algorithm are used to predict a categorical output variable , such as whether the email is spam or not. Regression is used to predict a continuous output variable , such as the price of a house or the temperature of a city.
Supervised Learning can be used in Image Recognition , Natural language processing and Recommendation System.
2. Unsupervised learning:- (Given: training data (without desired outputs)). The Unsupervised Learning is a type of Machine learning in which algorithm learn from the Unlabelled data i.e. the data does not have any pre-defined categories or labels. Instead , the algorithm must discovers the patterns and relationship in the data on its own.
It can be used for Anomaly Detection which is the process of Identifying data points that are different from the rest of the data.
3. Semi-supervised learning:- (Given: training data + a few desired outputs). Semi-supervised learning is a type of machine learning that combines elements of both supervised and unsupervised learning. In semi-supervised learning, the algorithm is trained on a dataset that contains both labeled and unlabeled examples. This means that only some of the data points in the training set have associated output labels, while the rest are unlabeled.
4. Reinforcement learning:- (Rewards from sequence of actions). The Reinforcement learning is a type of Machine Learning in which an agent learns to behave in an environemnt by trial and error. The Agent is rewarded for taking actions that lead to desired outcomes , and penalized for taking actions that lead to undesired outcomes. Overtime the agent learns to take the actions that maximize its expected reward.
Reinforcement learning is often used to train robots and other autonomous system.
Difference Between Machine Learning and Articificial Intelligence:
Articificial Intelligence is a concept of creating intelligent machines that stimulates human behavior whereas Machine Learning is a subset of AI that allows machine to learn from the data without being programmed.
Difference Between Machine Learning and Deep Learning:
Machine Learning is alternatively termed Shallow learning because it is very effective for smaller datasets. Deep Learning is extremely powerful when the dataset is large. Deep learning is a subset of machine learning that specifically focuses on neural networks with multiple layers.
Deep learning excels in tasks such as image and speech recognition, natural language processing , other complex tasks where large amounts of data can be leveraged. Unlike traditonal ML , deep learning algorithms automatically learn relevant features from the data , eliminating the need fo manual feature engineering.
ERRORS IN MACHINE LEARNING:

Bias and Variance in Machine Learning
Machine learning is a branch of Artificial Intelligence, which allows machines to perform data analysis and make predictions.
However, if the machine learning model is not accurate, it can make predictions errors, and these prediction errors are usually known as Bias and Variance.
In machine learning, these errors will always be present as there is always a slight difference between the model predictions and actual predictions. The main aim of ML/data science analysts is to reduce these errors in order to get more accurate results.
What is Bias ?
While making predictions, a difference occurs between prediction values made by the model and actual values/expected values, and this difference is known as bias errors or Errors due to bias.
It can be defined as an inability of machine learning algorithms such as Linear Regression to capture the true relationship between the data points. Each algorithm begins with some amount of bias because bias occurs from assumptions in the model, which makes the target function simple to learn.
Low Bias: A low bias model will closely match the training dataset.
High Bias: A model with a high bias would not match the dataset closely. A high bias model also cannot perform well on new data.
Some examples of machine learning algorithms with low bias are:
- Decision Trees
- K-Nearest Neighbors
- Support Vector Machines
Some examples of machine learning algorithms with high bias are:
- Linear Regression
- Logistic Regression
How to Mitigate Bias in Machine Learning:
- Use-High-Quality training data :- This Means making sure that the training data is accurate and complete.
- Audit Machine Learning model for bias :- This Involves testing the models on different groups of people to see if there is biaseness.
What is Variance ?
The Variance would specify the amount of variation in the prediction if the different training data was used.Variance tells that how much a random variable is different from its expected value.
Ideally , a model should not vary too much from one training dataset to another, which means the algorihtm should be good in understanding the hidden mapping between inputs and output variables.
Low Variance means there is small variation in the prediction of the target function with changes in the training data set. At the same time, High Variance shows a large variation in the prediction of the target function with changes in the training dataset.
Different Combinations of Bias-Variance :-
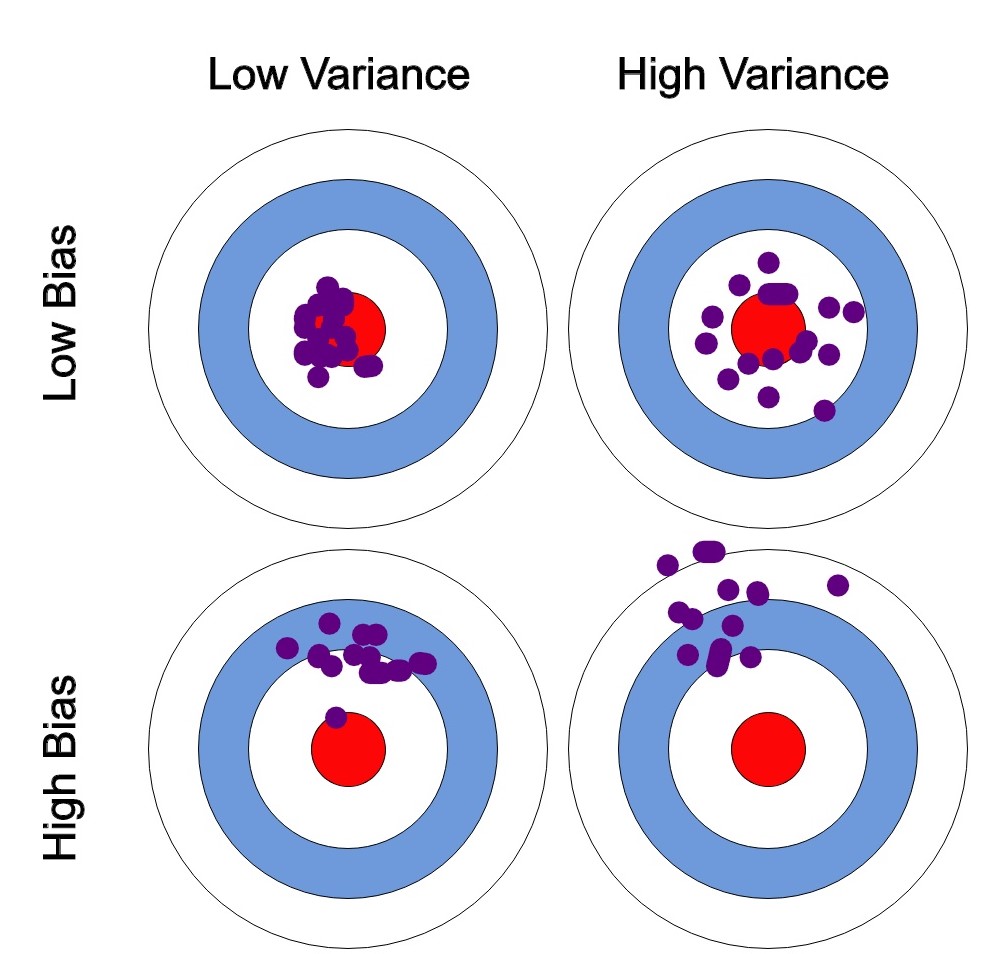
- Low-Bias, Low-Variance:The combination of low bias and low variance shows an ideal machine learning model.However, it is not possible practically.
- Low-Bias, High-Variance:With low bias and high variance, model predictions are inconsistent and accurate on average. This case occurs when model learns with a large number of parameters and hence leads to an overfitting.
- High-Bias, Low-Variance:With high bias and low variance, predictions are consistent but inaccurate on average, This case occurs when a model does not learn well with the training dataset or uses few numbers of the parameters. It leads to underfitting problems in the model.
- High-Bias, High-Variance:With high bias and high variance, predictions are inconsistent and also inaccurate on average.
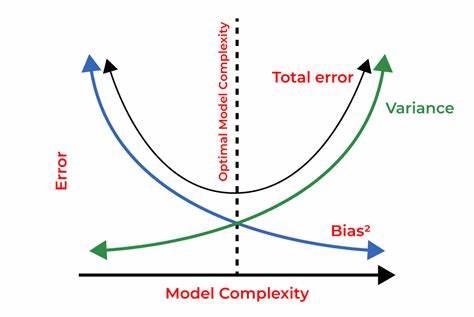
Bias-Variance Trade-Off :-
Overfitting
Overfitting occurs when our machine learning model tries to cover all the data points or more than the required data points present in the given dataset. Because of this, the model starts caching noise and inaccurate values present in the dataset, and all these factors reduce the efficiency and accuracy of the model. The overfitted model has low bias and high variance.
The chances of occurrence of overfitting increase as much we provide training to our model. It means the more we train our model, the more chances of occurring the overfitted model.
Overfitting is the main problem that occurs in supervised learning.
Overfitting Example:
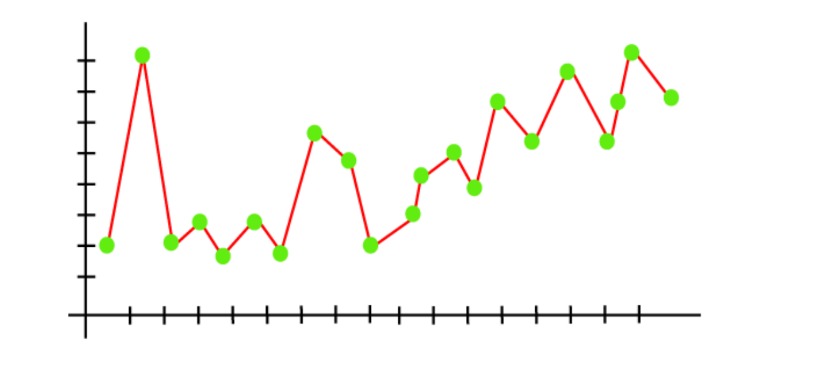
How to avoid the Overfitting in Model:
- Cross Validation
- Training with more data
- Removing features
- Early stopping
- Regularization
Underfitting
Underfitting occurs when our machine learning model is not able to capture the underlying trend of the data. the model is not able to learn enough from the training data , and hence it reduces the accuracy and produces unreliable predictions.
How to avoid underfitting:
- By increasing the training time of the model.
- By increasing the number of features.
Underfitting Example:
What is Gradient ?
A Gradient measures how much the output of a function changes if you change the inputs a little bit.
A Gradient simply measures the change in all weights with regard to the change in error. You can also think of a gradient as the slope of a function. The higher the gradient, the sleeper the slope and faster a model can learn. But if the slop is zero, the model stops learning.
What is Gradient Descent ?
Gradient Descent is defined as one of the most commonly used iterative optimization algoeithms of machine learning to train the machine learning model or deep learning models. It helps in finding the local minimum of a function.
The main objective of using a gradient descent algorithm is to minimize the cost function or the error between predicted value and actual value using iteration.
Next Page